# Mu: a human-scale computer
Mu is a minimal-dependency hobbyist computing stack (everything above the
processor and OS kernel).
Mu is not designed to operate in large clusters providing services for
millions of people. Mu is designed for _you_, to run one computer. (Or a few.)
Running the code you want to run, and nothing else.
```sh
$ git clone https://github.com/akkartik/mu
$ cd mu
$ ./subx
```
[](https://travis-ci.org/akkartik/mu)
## Goals
In priority order:
* [Reward curiosity.](http://akkartik.name/about)
* Easy to build, easy to run. [Minimal dependencies](https://news.ycombinator.com/item?id=16882140#16882555),
so that installation is always painless.
* All design decisions comprehensible to a single individual. (On demand.)
* All design decisions comprehensible without needing to talk to anyone.
(I always love talking to you, but I try hard to make myself redundant.)
* [A globally comprehensible _codebase_ rather than locally clean code.](http://akkartik.name/post/readable-bad)
* Clear error messages over expressive syntax.
* Safe.
* Thorough test coverage. If you break something you should immediately see
an error message. If you can manually test for something you should be
able to write an automated test for it.
* Memory leaks over memory corruption.
* Teach the computer bottom-up.
## Non-goals
* Efficiency. Clear programs over fast programs.
* Portability. Runs on any computer as long as it's x86.
* Compatibility. The goal is to get off mainstream stacks, not to perpetuate
them. Sometimes the right long-term solution is to [bump the major version number](http://akkartik.name/post/versioning).
* Syntax. Mu code is meant to be comprehended by [running, not just reading](http://akkartik.name/post/comprehension).
For now it's a thin veneer over machine code. I'm working on memory safety
before expressive syntax.
## What works so far
You get a thin syntax called SubX for programming in (a subset of) x86 machine
code. (A memory-safe compiled language is [being designed](http://akkartik.name/post/mu-2019-2).)
Here's a program (`examples/ex1.subx`) that returns 42:
```sh
bb/copy-to-ebx 0x2a/imm32 # 42 in hex
b8/copy-to-eax 1/imm32/exit
cd/syscall 0x80/imm8
```
You can generate tiny zero-dependency ELF binaries with it that run on Linux.
```sh
$ ./subx translate init.linux examples/ex1.subx -o examples/ex1 # on Linux or BSD or Mac
$ ./examples/ex1 # only on Linux
$ echo $?
42
```
(Running `subx` requires a C++ compiler, transparently invoking it as
necessary.)
You can run the generated binaries on an interpreter/VM for better error
messages.
```sh
$ ./subx run examples/ex1 # on Linux or BSD or Mac
$ echo $?
42
```
Emulated runs can generate a trace that permits [time-travel debugging](https://github.com/akkartik/mu/blob/master/browse_trace/Readme.md).
```sh
$ ./subx --debug translate init.linux examples/factorial.subx -o examples/factorial
saving address->label information to 'labels'
saving address->source information to 'source_lines'
$ ./subx --debug --trace run examples/factorial
saving trace to 'last_run'
$ ./browse_trace/browse_trace last_run # text-mode debugger UI
```
You can write tests for your programs. The entire stack is thoroughly covered
by automated tests. SubX's tagline: tests before syntax.
```sh
$ ./subx test
$ ./subx run apps/factorial test
```
You can use SubX to translate itself. For example, running natively on Linux:
```sh
# generate translator phases using the C++ translator
$ ./subx translate init.linux 0*.subx apps/subx-params.subx apps/hex.subx -o hex
$ ./subx translate init.linux 0*.subx apps/subx-params.subx apps/survey.subx -o survey
$ ./subx translate init.linux 0*.subx apps/subx-params.subx apps/pack.subx -o pack
$ ./subx translate init.linux 0*.subx apps/subx-params.subx apps/assort.subx -o assort
$ ./subx translate init.linux 0*.subx apps/subx-params.subx apps/dquotes.subx -o dquotes
$ ./subx translate init.linux 0*.subx apps/subx-params.subx apps/tests.subx -o tests
$ chmod +x hex survey pack assort dquotes tests
# use the generated translator phases to translate SubX programs
$ cat init.linux examples/ex1.subx |./tests |./dquotes |./assort |./pack |./survey |./hex > a.elf
$ chmod +x a.elf
$ ./a.elf
$ echo $?
42
# or, automating the above steps
$ ./ntranslate init.linux ex1.subx
$ ./a.elf
$ echo $?
42
```
Or, running in a VM on other platforms:
```sh
$ ./translate init.linux ex1.subx # generates identical a.elf to above
$ ./subx run a.elf
$ echo $?
42
```
You can package up SubX binaries with the minimal hobbyist OS [Soso](https://github.com/ozkl/soso)
and run them on Qemu. (Requires graphics and sudo access. Currently doesn't
work on a cloud server.)
```sh
# dependencies
$ sudo apt install util-linux nasm xorriso # maybe also dosfstools and mtools
# package up a "hello world" program with a third-party kernel into mu_soso.iso
# requires sudo
$ ./gen_soso_iso init.soso examples/ex6.subx
# try it out
$ qemu-system-i386 -cdrom mu_soso.iso
```
You can also package up SubX binaries with a Linux kernel and run them on
either Qemu or [a cloud server that supports custom images](http://akkartik.name/post/iso-on-linode).
(Takes 12 minutes with 8GB RAM. Requires 12 million LoC of C for the Linux
kernel; that number will gradually go down.)
```sh
$ sudo apt install build-essential flex bison wget libelf-dev libssl-dev xorriso
$ ./gen_linux_iso init.linux examples/ex6.subx
$ qemu-system-x86_64 -m 256M -cdrom mu.iso -boot d
```
## What it looks like
Here is the above example again:
```sh
bb/copy-to-ebx 0x2a/imm32 # 42 in hex
b8/copy-to-eax 1/imm32/exit
cd/syscall 0x80/imm8
```
Every line contains at most one instruction. Instructions consist of words
separated by whitespace. Words may be _opcodes_ (defining the operation being
performed) or _arguments_ (specifying the data the operation acts on). Any
word can have extra _metadata_ attached to it after `/`. Some metadata is
required (like the `/imm32` and `/imm8` above), but unrecognized metadata is
silently skipped so you can attach comments to words (like the instruction
name `/copy-to-eax` above, or the `/exit` operand).
SubX doesn't provide much syntax (there aren't even the usual mnemonics for
opcodes), but it _does_ provide error-checking. If you miss an operand or
accidentally add an extra operand you'll get a nice error. SubX won't arbitrarily
interpret bytes of data as instructions or vice versa.
So much for syntax. What do all these numbers actually _mean_? SubX supports a
small subset of the 32-bit x86 instruction set that likely runs on your
computer. (Think of the name as short for "sub-x86".) Instructions operate on
a few registers:
* Six general-purpose 32-bit registers: `eax`, `ebx`, `ecx`, `edx`, `esi` and
`edi`
* Two additional 32-bit registers: `esp` and `ebp` (I suggest you only use
these to manage the call stack.)
* Four 1-bit _flag_ registers for conditional branching:
- zero/equal flag `ZF`
- sign flag `SF`
- overflow flag `OF`
- carry flag `CF`
SubX programs consist of instructions like `89/copy`, `01/add`, `3d/compare`
and `51/push-ecx` which modify these registers as well as a byte-addressable
memory. For a complete list of supported instructions, run `subx help opcodes`.
(SubX doesn't support floating-point registers yet. Intel processors support
an 8-bit mode, 16-bit mode and 64-bit mode. SubX will never support them.
There are other flags. SubX will never support them. There are also _many_
more instructions that SubX will never support.)
It's worth distinguishing between an instruction's _operands_ and its _arguments_.
Arguments are provided directly in instructions. Operands are pieces of data
in register or memory that are operated on by instructions. Intel processors
determine operands from arguments in fairly complex ways.
## Lengthy interlude: How x86 instructions compute operands
The [Intel processor manual](http://www.intel.com/content/dam/www/public/us/en/documents/manuals/64-ia-32-architectures-software-developer-instruction-set-reference-manual-325383.pdf)
is the final source of truth on the x86 instruction set, but it can be
forbidding to make sense of, so here's a quick orientation. You will need
familiarity with binary numbers, and maybe a few other things. Email [me](mailto:mu@akkartik.com)
any time if something isn't clear. I love explaining this stuff for as long as
it takes. The bad news is that it takes some getting used to. The good news is
that internalizing the next 500 words will give you a significantly deeper
understanding of your computer.
Most instructions operate on an operand in register or memory ('reg/mem'), and
a second operand in a register. The register operand is specified fairly
directly using the 3-bit `/r32` argument:
- 0 means register `eax`
- 1 means register `ecx`
- 2 means register `edx`
- 3 means register `ebx`
- 4 means register `esp`
- 5 means register `ebp`
- 6 means register `esi`
- 7 means register `edi`
The reg/mem operand, however, gets complex. It can be specified by 1-7
arguments, each ranging in size from 2 bits to 4 bytes.
The key argument that's always present for reg/mem operands is `/mod`, the
_addressing mode_. This is a 2-bit argument that can take 4 possible values,
and it determines what other arguments are required, and how to interpret
them.
* If `/mod` is `3`: the operand is in the register described by the 3-bit
`/rm32` argument similarly to `/r32` above.
* If `/mod` is `0`: the operand is in the address provided in the register
described by `/rm32`. That's `*rm32` in C syntax.
* If `/mod` is `1`: the operand is in the address provided by adding the
register in `/rm32` with the (1-byte) displacement. That's `*(rm32 + /disp8)`
in C syntax.
* If `/mod` is `2`: the operand is in the address provided by adding the
register in `/rm32` with the (4-byte) displacement. That's `*(/rm32 +
/disp32)` in C syntax.
In the last three cases, one exception occurs when the `/rm32` argument
contains `4`. Rather than encoding register `esp`, it means the address is
provided by three _whole new_ arguments (`/base`, `/index` and `/scale`) in a
_totally_ different way (where `<<` is the left-shift operator):
```
reg/mem = *(base + (index << scale))
```
(There are a couple more exceptions ☹; see [Table 2-2](modrm.pdf) and [Table 2-3](sib.pdf)
of the Intel manual for the complete story.)
Phew, that was a lot to take in. Some examples to work through as you reread
and digest it:
1. To read directly from the `eax` register, `/mod` must be `3` (direct mode),
and `/rm32` must be `0`. There must be no `/base`, `/index` or `/scale`
arguments.
1. To read from `*eax` (in C syntax), `/mod` must be `0` (indirect mode), and
the `/rm32` argument must be `0`. There must be no `/base`, `/index` or
`/scale` arguments.
1. To read from `*(eax+4)`, `/mod` must be `1` (indirect + disp8 mode),
`/rm32` must be `0`, there must be no SIB byte, and there must be a single
displacement byte containing `4`.
1. To read from `*(eax+ecx+4)`, one approach would be to set `/mod` to `1` as
above, `/rm32` to `4` (SIB byte next), `/base` to `0`, `/index` to `1`
(`ecx`) and a single displacement byte to `4`. (What should the `scale` bits
be? Can you think of another approach?)
1. To read from `*(eax+ecx+1000)`, one approach would be:
- `/mod`: `2` (indirect + disp32)
- `/rm32`: `4` (`/base`, `/index` and `/scale` arguments required)
- `/base`: `0` (eax)
- `/index`: `1` (ecx)
- `/disp32`: 4 bytes containing `1000`
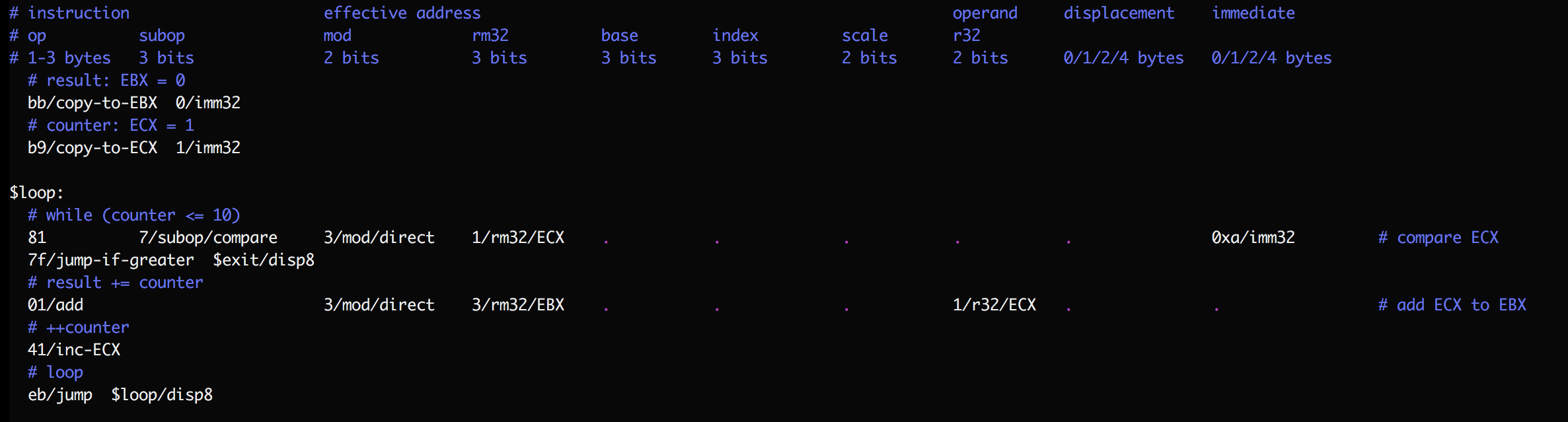
## Putting it all together
Here's a more meaty example:
This program sums the first 10 natural numbers. By convention I use horizontal
tabstops to help read instructions, dots to help follow the long lines,
comments before groups of instructions to describe their high-level purpose,
and comments at the end of complex instructions to state the low-level
operation they perform. Numbers are always in hexadecimal (base 16) and must
start with a digit ('0'..'9'); use the '0x' prefix when a number starts with a
letter ('a'..'f'). I tend to also include it as a reminder when numbers look
like decimal numbers.
Try running this example now:
```sh
$ ./subx translate init.linux examples/ex3.subx -o examples/ex3
$ ./subx run examples/ex3
$ echo $?
55
```
If you're on Linux you can also run it natively:
```sh
$ ./examples/ex3
$ echo $?
55
```
Use it now to follow along for a more complete tour of SubX syntax.
## The syntax of SubX programs
SubX programs map to the same ELF binaries that a conventional Linux system
uses. Linux ELF binaries consist of a series of _segments_. In particular, they
distinguish between code and data. Correspondingly, SubX programs consist of a
series of segments, each starting with a header line: `==` followed by a name
and approximate starting address.
All code must lie in a segment called 'code'.
Segments can be added to.
```sh
== code 0x09000000 # first mention requires starting address
...A...
== data 0x0a000000
...B...
== code # no address necessary when adding
...C...
```
The `code` segment now contains the instructions of `A` as well as `C`.
Within the `code` segment, each line contains a comment, label or instruction.
Comments start with a `#` and are ignored. Labels should always be the first
word on a line, and they end with a `:`.
Instruction arguments must specify their type, from:
- `/mod`
- `/rm32`
- `/r32`
- `/subop` (sometimes the `/r32` bits in an instruction are used as an extra opcode)
- displacement: `/disp8` or `/disp32`
- immediate: `/imm8` or `/imm32`
Different instructions (opcodes) require different arguments. SubX will
validate each instruction in your programs, and raise an error anytime you
miss or spuriously add an argument.
I recommend you order arguments consistently in your programs. SubX allows
arguments in any order, but only because that's simplest to explain/implement.
Switching order from instruction to instruction is likely to add to the
reader's burden. Here's the order I've been using after opcodes:
```
|<--------- reg/mem --------->| |<- reg/mem? ->|
/subop /mod /rm32 /base /index /scale /r32 /displacement /immediate
```
Instructions can refer to labels in displacement or immediate arguments, and
they'll obtain a value based on the address of the label: immediate arguments
will contain the address directly, while displacement arguments will contain
the difference between the address and the address of the current instruction.
The latter is mostly useful for `jump` and `call` instructions.
Functions are defined using labels. By convention, labels internal to functions
(that must only be jumped to) start with a `$`. Any other labels must only be
called, never jumped to. All labels must be unique.
A special label is `Entry`, which can be used to specify/override the entry
point of the program. It doesn't have to be unique, and the latest definition
will override earlier ones.
(The `Entry` label, along with duplicate segment headers, allows programs to
be built up incrementally out of multiple [_layers_](http://akkartik.name/post/wart-layers).)
The data segment consists of labels as before and byte values. Referring to
data labels in either `code` segment instructions or `data` segment values
yields their address.
Automatic tests are an important part of SubX, and there's a simple mechanism
to provide a test harness: all functions that start with `test-` are called in
turn by a special, auto-generated function called `run-tests`. How you choose
to call it is up to you.
I try to keep things simple so that there's less work to do when I eventually
implement SubX in SubX. But there _is_ one convenience: instructions can
provide a string literal surrounded by quotes (`"`) in an `imm32` argument.
SubX will transparently copy it to the `data` segment and replace it with its
address. Strings are the only place where a SubX word is allowed to contain
spaces.
That should be enough information for writing SubX programs. The `examples/`
directory provides some fodder for practice, giving a more gradual introduction
to SubX features. This repo includes the binary for all examples. At any
commit, an example's binary should be identical bit for bit with the result of
translating the corresponding `.subx` file. The binary should also be natively
runnable on a Linux system running on Intel x86 processors, either 32- or
64-bit. If either of these invariants is broken it's a bug on my part.
## Running
`subx` currently has the following sub-commands:
* `subx help`: some helpful documentation to have at your fingertips.
* `subx test`: runs all automated tests.
* `subx translate -o
 This program sums the first 10 natural numbers. By convention I use horizontal
tabstops to help read instructions, dots to help follow the long lines,
comments before groups of instructions to describe their high-level purpose,
and comments at the end of complex instructions to state the low-level
operation they perform. Numbers are always in hexadecimal (base 16) and must
start with a digit ('0'..'9'); use the '0x' prefix when a number starts with a
letter ('a'..'f'). I tend to also include it as a reminder when numbers look
like decimal numbers.
Try running this example now:
```sh
$ ./subx translate init.linux examples/ex3.subx -o examples/ex3
$ ./subx run examples/ex3
$ echo $?
55
```
If you're on Linux you can also run it natively:
```sh
$ ./examples/ex3
$ echo $?
55
```
Use it now to follow along for a more complete tour of SubX syntax.
## The syntax of SubX programs
SubX programs map to the same ELF binaries that a conventional Linux system
uses. Linux ELF binaries consist of a series of _segments_. In particular, they
distinguish between code and data. Correspondingly, SubX programs consist of a
series of segments, each starting with a header line: `==` followed by a name
and approximate starting address.
All code must lie in a segment called 'code'.
Segments can be added to.
```sh
== code 0x09000000 # first mention requires starting address
...A...
== data 0x0a000000
...B...
== code # no address necessary when adding
...C...
```
The `code` segment now contains the instructions of `A` as well as `C`.
Within the `code` segment, each line contains a comment, label or instruction.
Comments start with a `#` and are ignored. Labels should always be the first
word on a line, and they end with a `:`.
Instruction arguments must specify their type, from:
- `/mod`
- `/rm32`
- `/r32`
- `/subop` (sometimes the `/r32` bits in an instruction are used as an extra opcode)
- displacement: `/disp8` or `/disp32`
- immediate: `/imm8` or `/imm32`
Different instructions (opcodes) require different arguments. SubX will
validate each instruction in your programs, and raise an error anytime you
miss or spuriously add an argument.
I recommend you order arguments consistently in your programs. SubX allows
arguments in any order, but only because that's simplest to explain/implement.
Switching order from instruction to instruction is likely to add to the
reader's burden. Here's the order I've been using after opcodes:
```
|<--------- reg/mem --------->| |<- reg/mem? ->|
/subop /mod /rm32 /base /index /scale /r32 /displacement /immediate
```
Instructions can refer to labels in displacement or immediate arguments, and
they'll obtain a value based on the address of the label: immediate arguments
will contain the address directly, while displacement arguments will contain
the difference between the address and the address of the current instruction.
The latter is mostly useful for `jump` and `call` instructions.
Functions are defined using labels. By convention, labels internal to functions
(that must only be jumped to) start with a `$`. Any other labels must only be
called, never jumped to. All labels must be unique.
A special label is `Entry`, which can be used to specify/override the entry
point of the program. It doesn't have to be unique, and the latest definition
will override earlier ones.
(The `Entry` label, along with duplicate segment headers, allows programs to
be built up incrementally out of multiple [_layers_](http://akkartik.name/post/wart-layers).)
The data segment consists of labels as before and byte values. Referring to
data labels in either `code` segment instructions or `data` segment values
yields their address.
Automatic tests are an important part of SubX, and there's a simple mechanism
to provide a test harness: all functions that start with `test-` are called in
turn by a special, auto-generated function called `run-tests`. How you choose
to call it is up to you.
I try to keep things simple so that there's less work to do when I eventually
implement SubX in SubX. But there _is_ one convenience: instructions can
provide a string literal surrounded by quotes (`"`) in an `imm32` argument.
SubX will transparently copy it to the `data` segment and replace it with its
address. Strings are the only place where a SubX word is allowed to contain
spaces.
That should be enough information for writing SubX programs. The `examples/`
directory provides some fodder for practice, giving a more gradual introduction
to SubX features. This repo includes the binary for all examples. At any
commit, an example's binary should be identical bit for bit with the result of
translating the corresponding `.subx` file. The binary should also be natively
runnable on a Linux system running on Intel x86 processors, either 32- or
64-bit. If either of these invariants is broken it's a bug on my part.
## Running
`subx` currently has the following sub-commands:
* `subx help`: some helpful documentation to have at your fingertips.
* `subx test`: runs all automated tests.
* `subx translate -o
This program sums the first 10 natural numbers. By convention I use horizontal
tabstops to help read instructions, dots to help follow the long lines,
comments before groups of instructions to describe their high-level purpose,
and comments at the end of complex instructions to state the low-level
operation they perform. Numbers are always in hexadecimal (base 16) and must
start with a digit ('0'..'9'); use the '0x' prefix when a number starts with a
letter ('a'..'f'). I tend to also include it as a reminder when numbers look
like decimal numbers.
Try running this example now:
```sh
$ ./subx translate init.linux examples/ex3.subx -o examples/ex3
$ ./subx run examples/ex3
$ echo $?
55
```
If you're on Linux you can also run it natively:
```sh
$ ./examples/ex3
$ echo $?
55
```
Use it now to follow along for a more complete tour of SubX syntax.
## The syntax of SubX programs
SubX programs map to the same ELF binaries that a conventional Linux system
uses. Linux ELF binaries consist of a series of _segments_. In particular, they
distinguish between code and data. Correspondingly, SubX programs consist of a
series of segments, each starting with a header line: `==` followed by a name
and approximate starting address.
All code must lie in a segment called 'code'.
Segments can be added to.
```sh
== code 0x09000000 # first mention requires starting address
...A...
== data 0x0a000000
...B...
== code # no address necessary when adding
...C...
```
The `code` segment now contains the instructions of `A` as well as `C`.
Within the `code` segment, each line contains a comment, label or instruction.
Comments start with a `#` and are ignored. Labels should always be the first
word on a line, and they end with a `:`.
Instruction arguments must specify their type, from:
- `/mod`
- `/rm32`
- `/r32`
- `/subop` (sometimes the `/r32` bits in an instruction are used as an extra opcode)
- displacement: `/disp8` or `/disp32`
- immediate: `/imm8` or `/imm32`
Different instructions (opcodes) require different arguments. SubX will
validate each instruction in your programs, and raise an error anytime you
miss or spuriously add an argument.
I recommend you order arguments consistently in your programs. SubX allows
arguments in any order, but only because that's simplest to explain/implement.
Switching order from instruction to instruction is likely to add to the
reader's burden. Here's the order I've been using after opcodes:
```
|<--------- reg/mem --------->| |<- reg/mem? ->|
/subop /mod /rm32 /base /index /scale /r32 /displacement /immediate
```
Instructions can refer to labels in displacement or immediate arguments, and
they'll obtain a value based on the address of the label: immediate arguments
will contain the address directly, while displacement arguments will contain
the difference between the address and the address of the current instruction.
The latter is mostly useful for `jump` and `call` instructions.
Functions are defined using labels. By convention, labels internal to functions
(that must only be jumped to) start with a `$`. Any other labels must only be
called, never jumped to. All labels must be unique.
A special label is `Entry`, which can be used to specify/override the entry
point of the program. It doesn't have to be unique, and the latest definition
will override earlier ones.
(The `Entry` label, along with duplicate segment headers, allows programs to
be built up incrementally out of multiple [_layers_](http://akkartik.name/post/wart-layers).)
The data segment consists of labels as before and byte values. Referring to
data labels in either `code` segment instructions or `data` segment values
yields their address.
Automatic tests are an important part of SubX, and there's a simple mechanism
to provide a test harness: all functions that start with `test-` are called in
turn by a special, auto-generated function called `run-tests`. How you choose
to call it is up to you.
I try to keep things simple so that there's less work to do when I eventually
implement SubX in SubX. But there _is_ one convenience: instructions can
provide a string literal surrounded by quotes (`"`) in an `imm32` argument.
SubX will transparently copy it to the `data` segment and replace it with its
address. Strings are the only place where a SubX word is allowed to contain
spaces.
That should be enough information for writing SubX programs. The `examples/`
directory provides some fodder for practice, giving a more gradual introduction
to SubX features. This repo includes the binary for all examples. At any
commit, an example's binary should be identical bit for bit with the result of
translating the corresponding `.subx` file. The binary should also be natively
runnable on a Linux system running on Intel x86 processors, either 32- or
64-bit. If either of these invariants is broken it's a bug on my part.
## Running
`subx` currently has the following sub-commands:
* `subx help`: some helpful documentation to have at your fingertips.
* `subx test`: runs all automated tests.
* `subx translate -o